





AWS supports trusted identity propagation, a feature that allows AWS services to securely propagate a user’s identity across service boundaries. With trusted identity propagation, you have fine-grained access controls based on a physical user’s identity rather than relying on IAM roles. This integration allows for the implementation of access control through services such as Amazon S3 Access Grants and maintains detailed audit logs of user actions across supported AWS services such as Amazon EMR. Furthermore, it supports long-running user background sessions for training jobs, so you can log out of your interactive ML application while the background job continues to run.
Amazon SageMaker Studio now supports trusted identity propagation, offering a powerful solution for enterprises seeking to enhance their ML system security. By integrating trusted identity propagation with SageMaker Studio, organizations can simplify access management by granting permissions to existing AWS IAM Identity Center identities.
In this post, we explore how to enable and use trusted identity propagation in SageMaker Studio, demonstrating its benefits through practical use cases and implementation guidelines. We walk through the setup process, discuss key considerations, and showcase how this feature can transform your organization’s approach to security and access controls.
Solution overview
In this section, we review the architecture for the proposed solution and the steps to enable trusted identity propagation for your SageMaker Studio domain.
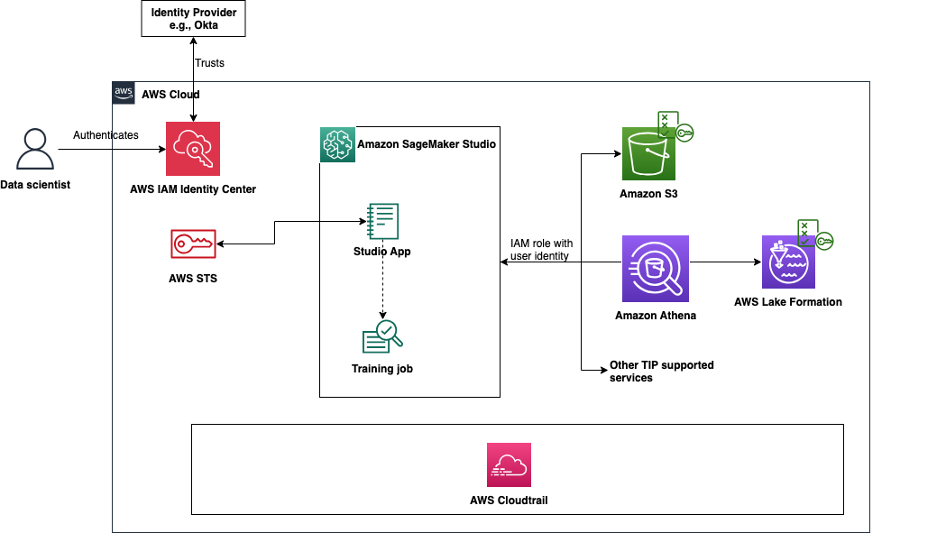
The following diagram shows the interaction between the different components that allow the user’s identity to propagate from their identity provider and IAM Identity Center to downstream services such as Amazon EMR and Amazon Athena.
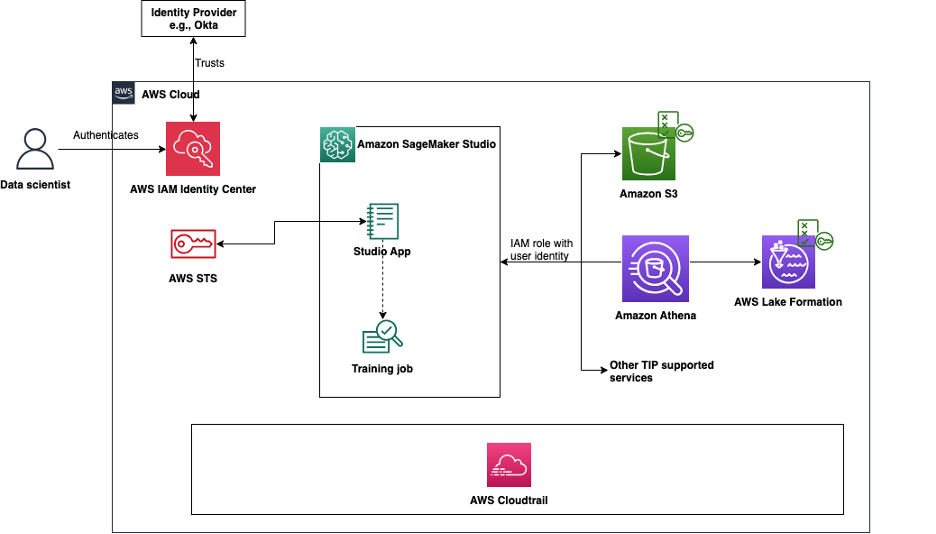

With a trusted identity propagation-enabled SageMaker Studio domain, users can access data across supported AWS services using their end user identity and group membership, in addition to access allowed by their domain or user execution role. In addition, API calls from SageMaker Studio notebooks and supported AWS services and Amazon SageMaker AI features log the user identity in AWS CloudTrail. For a list of supported AWS services and SageMaker AI features, see Trusted identity propagation architecture and compatibility. In the following sections, we show how to enable trusted identity propagation for your domain.
This solution applies for SageMaker Studio domains set up using IAM Identity Center as the method of authentication. If your domain is set up using IAM, see Implement user-level access control for multi-tenant ML platforms on Amazon SageMaker AI for best practices on managing and scaling access control.
Prerequisites
To follow along with this post, you must have the following:
- An AWS account with an organization instance of IAM Identity Center configured through AWS Organizations
- Administrator permissions (or elevated permissions allowing modification of IAM principals, and SageMaker administrator access to create and update domains)
Create or update the SageMaker execution role
For trusted identity propagation to work, the SageMaker execution role (domain and user profile execution role), should allow the sts:SetContext permissions, in addition to sts:AssumeRole, in its trust policy. For a new SageMaker AI domain, create a domain execution role by following the instructions in Create execution role. For existing domains, follow the instructions in Get your execution role to find the user or domain’s execution role.
Next, to update the trust policy for the role, complete the following steps:
- In the navigation pane of the IAM console, choose Roles.
- In the list of roles in your account, choose the domain or user execution role.
- On the Trust relationships tab, choose Edit trust policy.
- Update the trust policy with the following statement:
- Choose Update policy to save your changes.
Trusted identity propagation only works for private spaces at the time of launch.
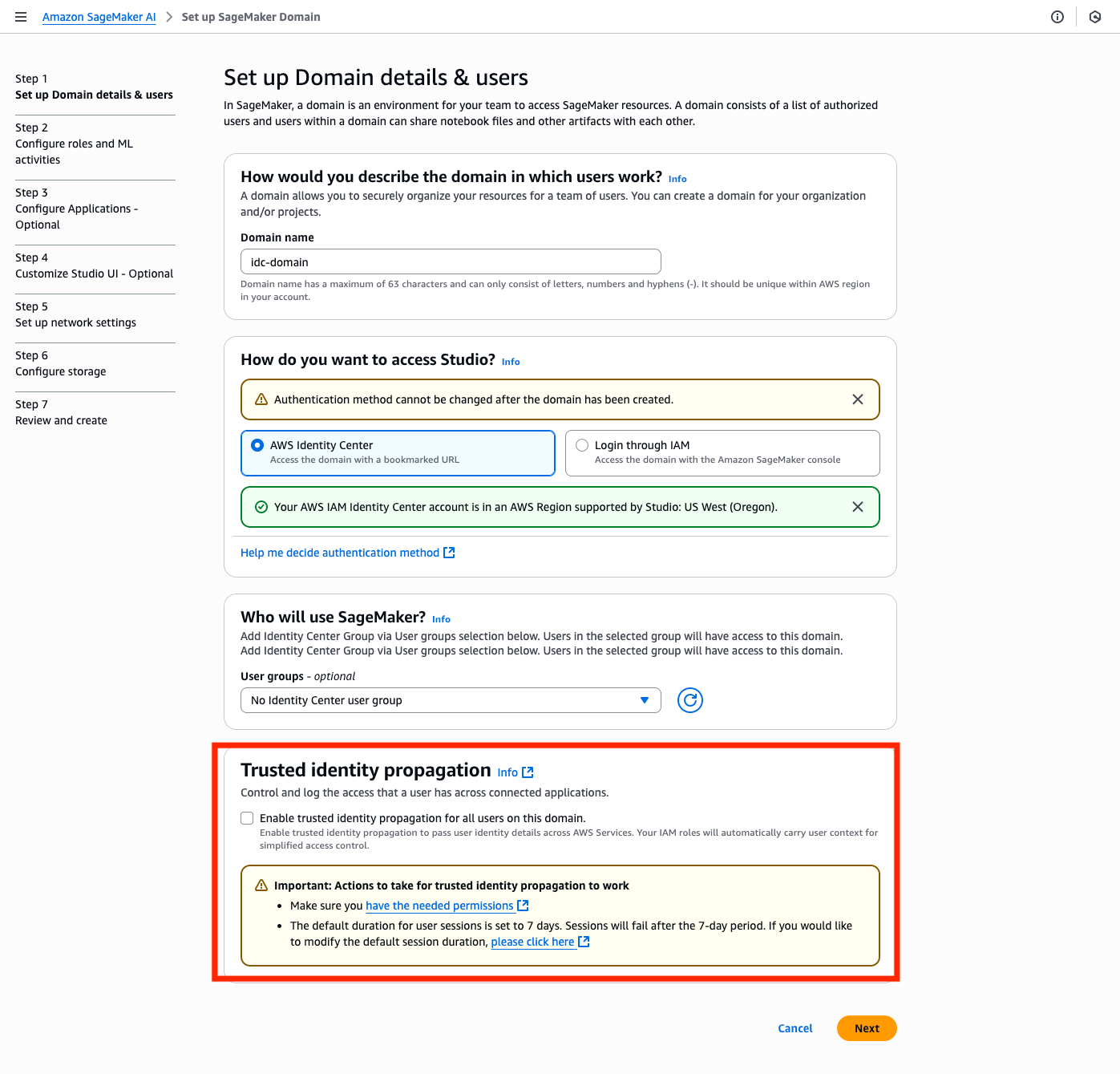
Create a SageMaker AI domain with trusted identity propagation enabled
SageMaker AI domains using IAM Identity Center for authentication can only be set up in the same AWS Region as the IAM Identity Center instance. To create a new SageMaker domain, follow the steps in Use custom setup for Amazon SageMaker AI. For Trusted identity propagation, select Enable trusted identity propagation for all users on this domain, and continue with the rest of the setup to create a domain and assign users and groups, choosing the role you created in the previous step.

Update an existing SageMaker AI domain
You can also update your existing SageMaker AI domain to enable trusted identity propagation. You can enable trusted identity propagation even while the domain or user has active SageMaker Studio applications. However, for the changes to be applied, the active applications must be restarted. You can use the EffectiveTrustedIdentityPropagationStatus field in the response to the DescribeApp API for running applications to determine if the application has trusted identity propagation enabled.
To enable trusted identity propagation for the domain using the SageMaker AI console, choose Edit under Authentication and permissions on the Domain settings tab.
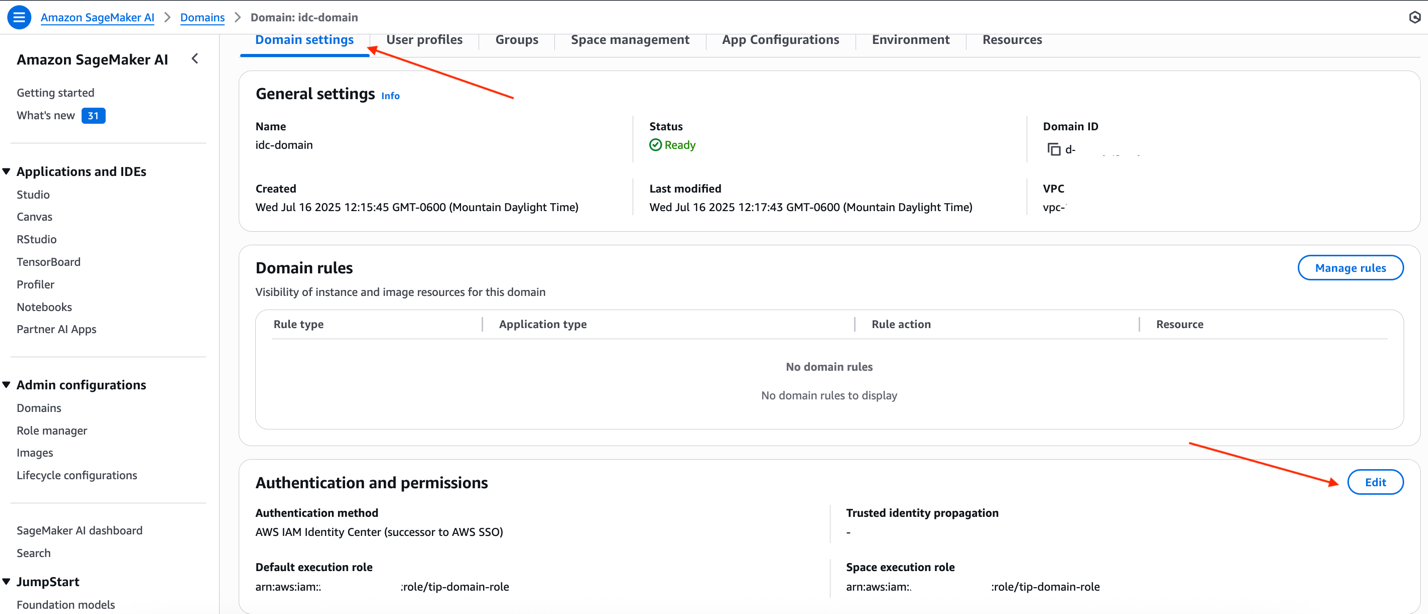

For Trusted identity propagation, select Enable trusted identity propagation for all users on this domain, and choose Submit to save the changes.
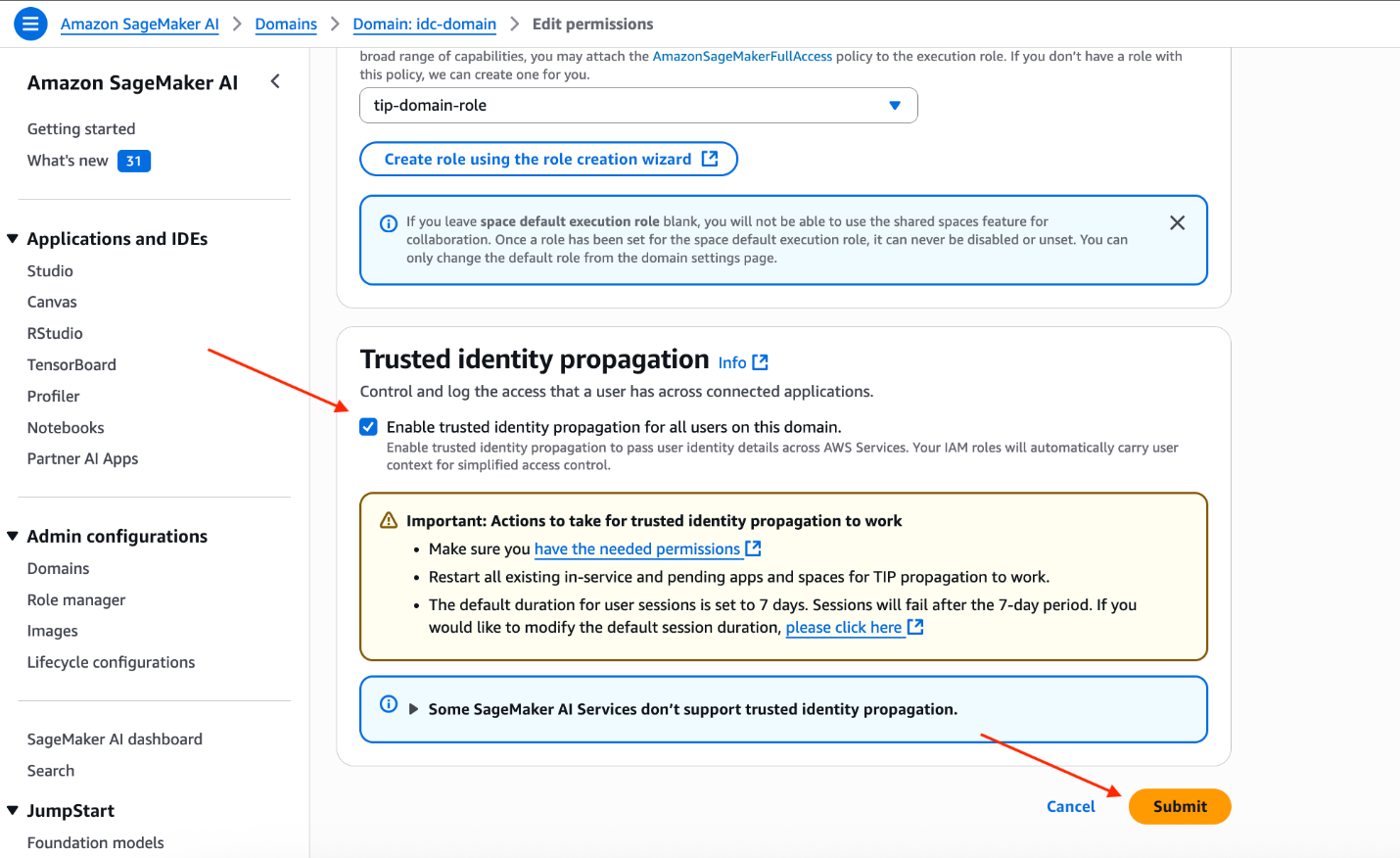

(Optional) Update user background session configuration in IAM Identity Center
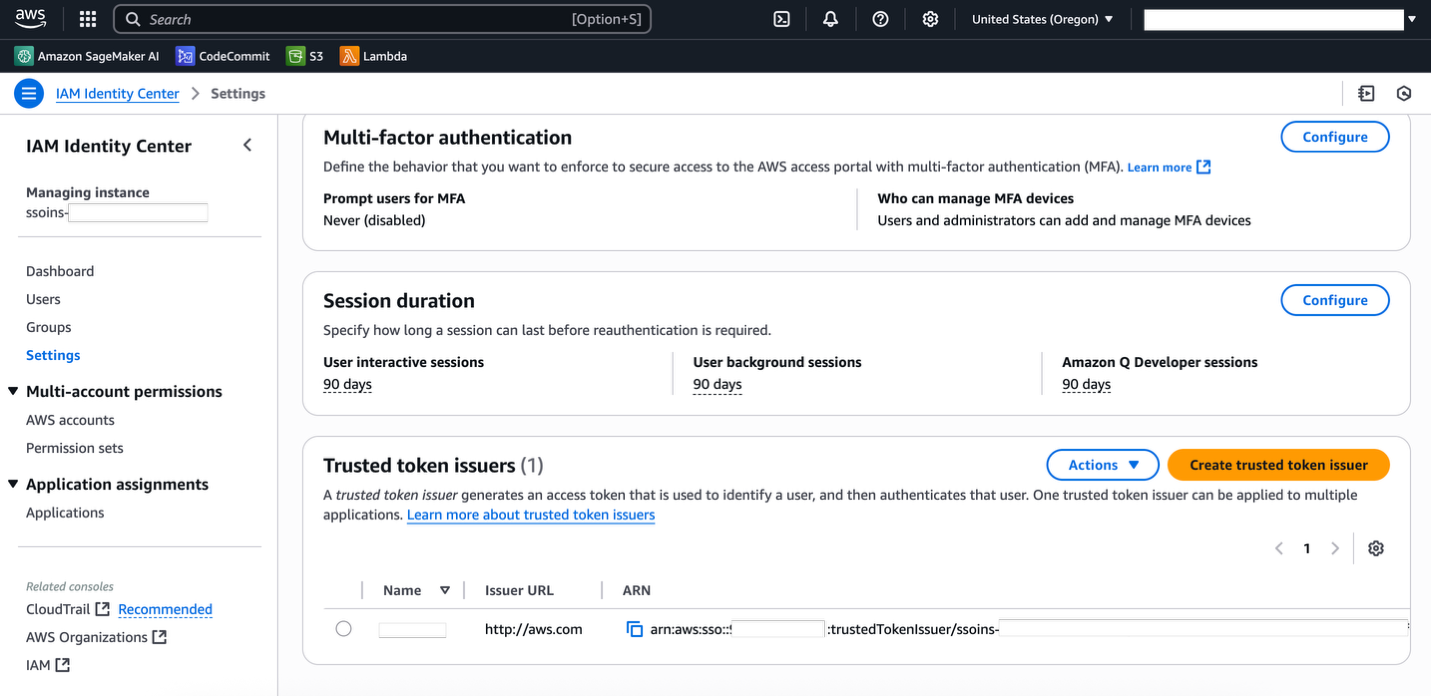
IAM Identity Center now supports running user background sessions, and the session duration is set by default to 7 days. With background sessions, users can launch long-running SageMaker training jobs that assume the user’s identity context along with the SageMaker execution role. As an administrator, you can enable or disable user background sessions, and modify the session duration for user background sessions. As of the time of writing, the maximum session duration that you can set for user background sessions is 90 days. The user’s session is stopped at the end of the specified duration, and consequently, the training job will also fail at the end of the session duration.
To disable or update the session duration, navigate to the IAM Identity Center console, choose Settings in the navigation pane, and choose Configure under Session duration.

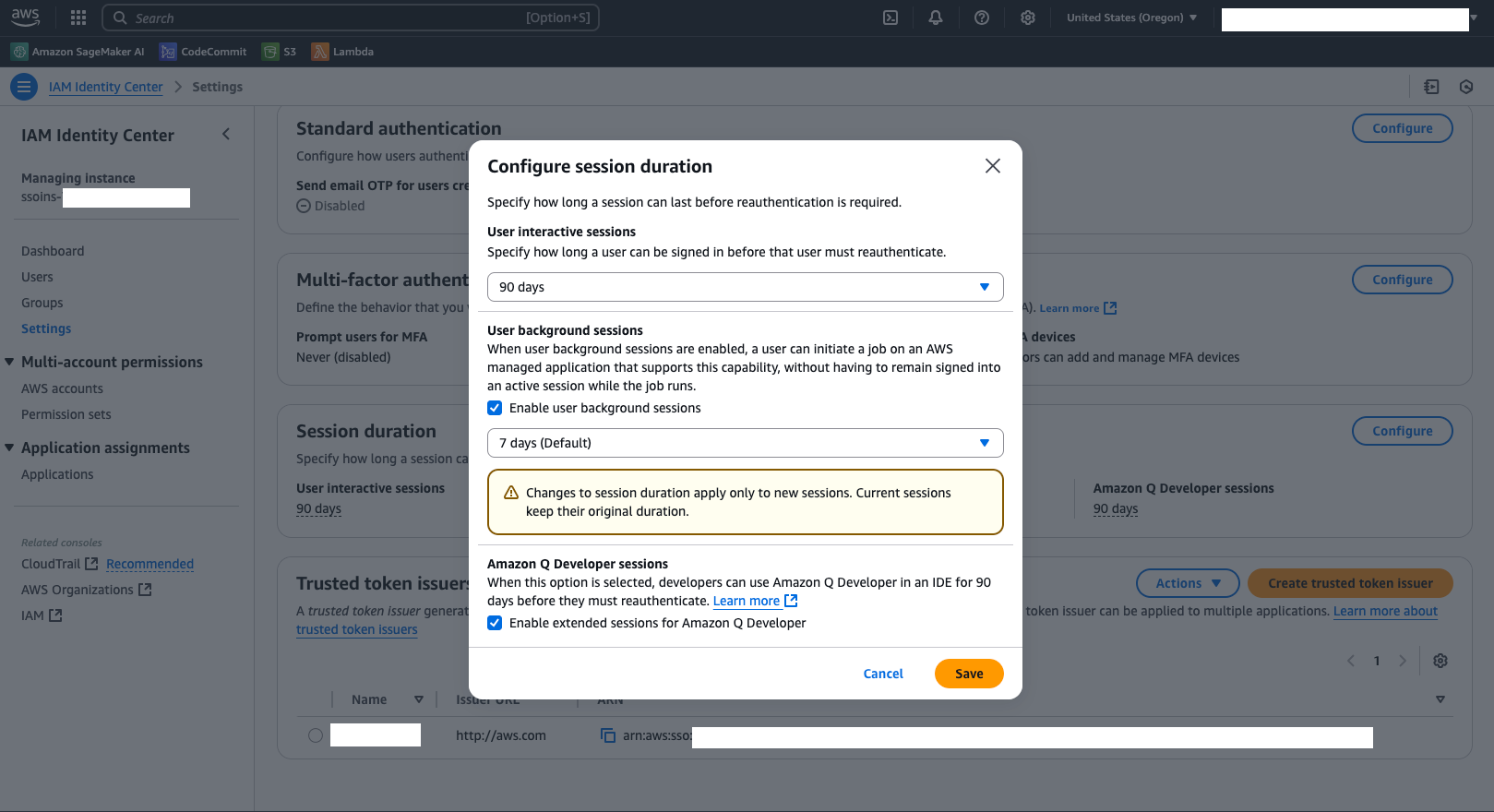
For User background sessions, select Enable user background sessions and use the dropdown to change the session duration. If user background sessions are disabled, the user must be logged in for the duration of the training job; otherwise, the training job will fail once the user logs out. Updating this configuration doesn’t affect current running sessions and only applies to newly created user background sessions. Choose Save to save your settings.

Use cases
Imagine you’re an enterprise with hundreds or even thousands of users, each requiring varying levels of access to data across multiple teams. You’re responsible for maintaining an AI/ML system on SageMaker AI and managing access permissions across diverse data sources such as Amazon Simple Storage Service (Amazon S3), Amazon Redshift, and AWS Lake Formation. Traditionally, this has involved maintaining complex IAM policies for users, services, and resources, including bucket policies where applicable. This approach is not only tedious but also makes it challenging to track and audit data access without maintaining a separate role for each user.
This is precisely the scenario that trusted identity propagation aims to address. With trusted identity propagation support, you can now maintain service-specific roles with minimal permissions, such as s3:GetDataAccess or LakeFormation:GetDataAccess, along with additional permissions to start jobs, view job statuses, and perform other necessary tasks. For data access, you can assign fine-grained policies directly to individual users. For instance, Jane might have read access to customer data and full access to sales and pricing data, whereas Laura might only have read access to sales trends. Both Jane and Laura can assume the same SageMaker AI role to access their SageMaker Studio applications, while maintaining separate data access permissions based on their individual identities.In the following sections, we explore how this can be achieved for common use cases, demonstrating the power and flexibility of trusted identity propagation in simplifying data access management while maintaining robust security and auditability.
Scenario 1: Experiment with Amazon S3 data in notebooks
S3 Access Grants provide a simplified way to manage data access at scale. Unlike traditional IAM roles and policies that require a detailed knowledge of IAM concepts, and frequent policy updates as new resources are added, with S3 Access Grants, you can define access to data based on familiar database-like grants that automatically scale with your data. This approach significantly reduces the operational overhead of managing thousands of IAM policies and bucket policies, and overcomes the limitations of IAM permissions, while strengthening security through access patterns. If you don’t have S3 Access Grants set up, see Create an S3 Access Grant instance to get started. For detailed architecture and use cases, you can also refer to Scaling data access with Amazon S3 Access Grants. After you have set up S3 Access Grants, you can grant access to your datasets to users based on their identity in IAM Identity Center.
To use S3 Access Grants from SageMaker Studio, update the following IAM roles with policies and trust policies.
For the domain or user execution role, add the following inline policy:
Make sure the S3 Access Grants role’s trust policy allows the sts:SetContext action in addition to sts:AssumeRole. The following is a sample trust policy:
GetDataAccess API to return temporary credentials, and by assuming the temporary credentials to read or write to their prefixes. For example, the following code shows how to use Boto3 to get temporary credentials and assume the credentials to get access to Amazon S3 locations that are allowed through S3 Access Grants:
Scenario 2: Access Lake Formation through Athena
Lake Formation provides centralized governance and fine-grained access control management for data stored in Amazon S3 and metadata in the AWS Glue Data Catalog. The Lake Formation permission model operates in conjunction with IAM permissions, offering granular controls at the database, table, column, row, and cell levels. This dual-layer security model provides comprehensive data governance while maintaining flexibility in access patterns.
Data governed through Lake Formation can be accessed through various AWS analytics services. In this scenario, we demonstrate using Athena, a serverless query engine that integrates seamlessly with Lake Formation’s permission model. For other services like Amazon EMR on EC2, make sure the resource is configured to support trusted identity propagation, including setting up security configurations and making sure the EMR cluster is configured with IAM roles that support trusted identity propagation.
The following instructions assume that you have already set up Lake Formation. If not, see Set up AWS Lake Formation and follow the AWS Lake Formation tutorials to set up Lake Formation and bring in your data.
Complete the following steps to access your governed data in trusted identity propagation-enabled SageMaker Studio notebooks using Athena:
- Integrate Lake Formation with IAM Identity Center by following the instructions in Integrating IAM Identity Center. At a high level, this includes creating an IAM role allowing creating and updating application configurations in Lake Formation and IAM Identity Center, and providing the single sign-on (SSO) instance ID.
- Grant permissions to the IAM Identity Center user to the relevant resources (database, table, row or column) using Lake Formation. See Granting permissions on Data Catalog resources instructions.
- Create an Athena workgroup that supports trusted identity propagation by following instructions in Create a workgroup and choosing IAM Identity Center as the method of authentication. Make sure the user has access to write to the query results location provided here using S3 Access Grants, because Athena uses access grants by default when choosing IAM Identity Center as the authentication method.
- Update the Athena workgroup’s IAM role with the following trust policy (add
sts:SetContextto the existing trust policy). You can find the IAM role by choosing the workgroup you created earlier and looking for Role name.
The setup is now complete. You can now launch SageMaker Studio using an IAM Identity Center user, launch a JupyterLab or Code Editor application, and query the database. See the following example code to get started:
Scenario 3: Create a training job supported with user background sessions
For a trusted identity propagation-enabled domain, a user background session is a session that continues to run even if the end-user has logged out of their interactive session such as JupyterLab applications in SageMaker Studio. For example, the user can initiate a training job from their SageMaker Studio space, and the job can run in the background for days or weeks regardless of the user’s activity, and use the user’s identity to access data and log audit trails. If your domain doesn’t have trusted identity propagation enabled, you can continue to run training jobs and processing jobs as before; however, if trusted identity propagation is enabled, make sure your user background session time is updated to reflect the duration of your training jobs, because the default is set automatically to 7 days. If you have enabled user background sessions, update your SageMaker Studio domain or user’s execution role with the following permissions to provide a seamless experience for data scientists:
With this setup, a data scientist can use an Amazon S3 location that they have access to through S3 Access Grants. SageMaker automatically looks for data access using S3 Access Grants and falls back to the job’s IAM role otherwise. For example, in the following SDK call to create the training job, the user provides the S3 Amazon URI where the data is stored, they have access to it through S3 Access Grants, and they can run this job without additional setup:
(Optional) View and manage user background sessions on IAM Identity Center
When training jobs are run as user background sessions, you can view these sessions as user background sessions on IAM Identity Center. The administrator can view a list of all user background sessions and optionally stop a session if the user has left the team, for example. When the user background session is ended, the training job subsequently fails.
To view a list of all user background sessions, on the IAM Identity Center console, choose Users and choose the user you want view the user background sessions for. Choose the Active sessions tab to view a list of sessions. The user background session can be identified by the Session type column, which shows if the session is interactive or a user background session. The list also shows the job’s Amazon Resource Name (ARN) under the Used by column.
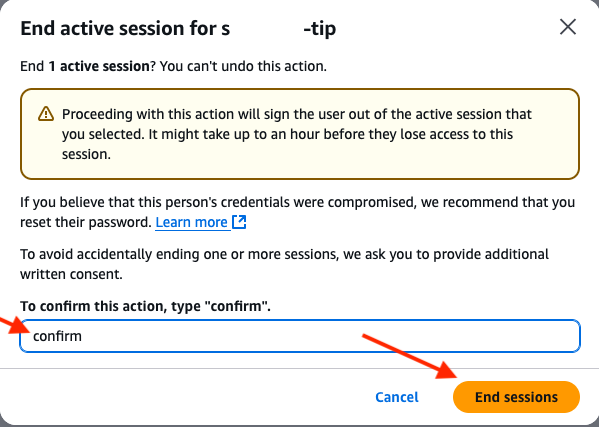
To end a session, select the session and choose End sessions.
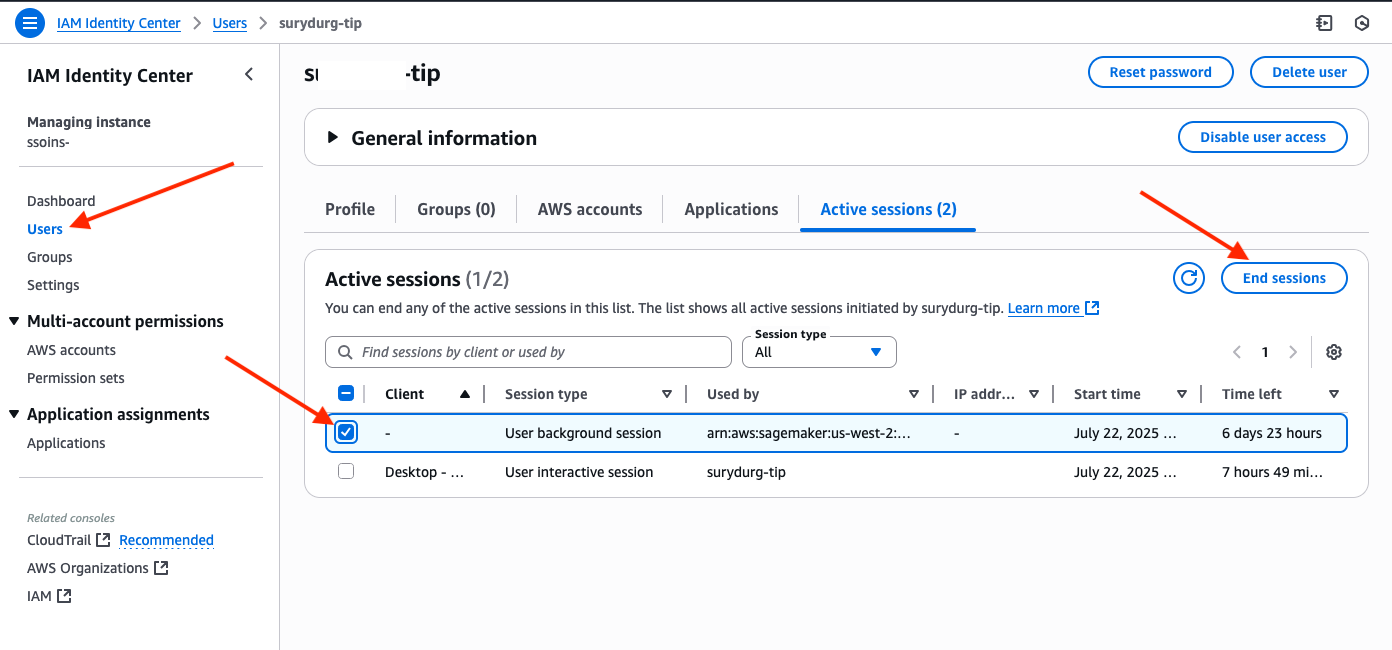

You will be prompted to confirm the action. Enter confirm to confirm that you want to end the session and choose End sessions to stop the user background session.

Scenario 4: Auditing using CloudTrail
After trusted identity propagation is enabled for your domain, you can now track the user that performed specific actions through CloudTrail. To try this out, log in to SageMaker Studio, and create and open a JupyterLab space. Open a terminal and enter aws s3 ls to list the available buckets in your Region.
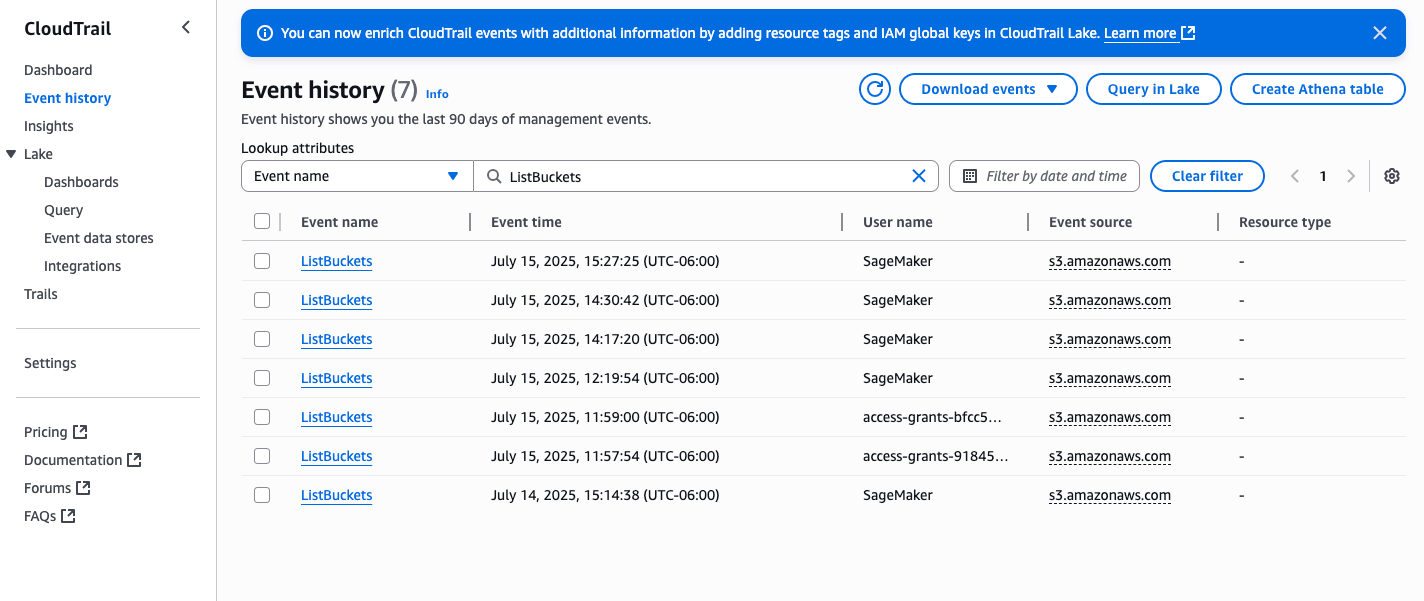
On the CloudTrail console, choose Event history in the navigation pane. Update the Lookup attributes to Event name and in the search box, enter ListBuckets. You should see a list of events, as shown in the following screenshot (it might take up to 5 minutes for the logs to be available in CloudTrail).

Choose the event to view its details (verify the user name is SageMaker if you have also listed buckets through the AWS console or APIs). In the event details, you should be able to see an additional field called onBehalfOf that has the user’s identity.
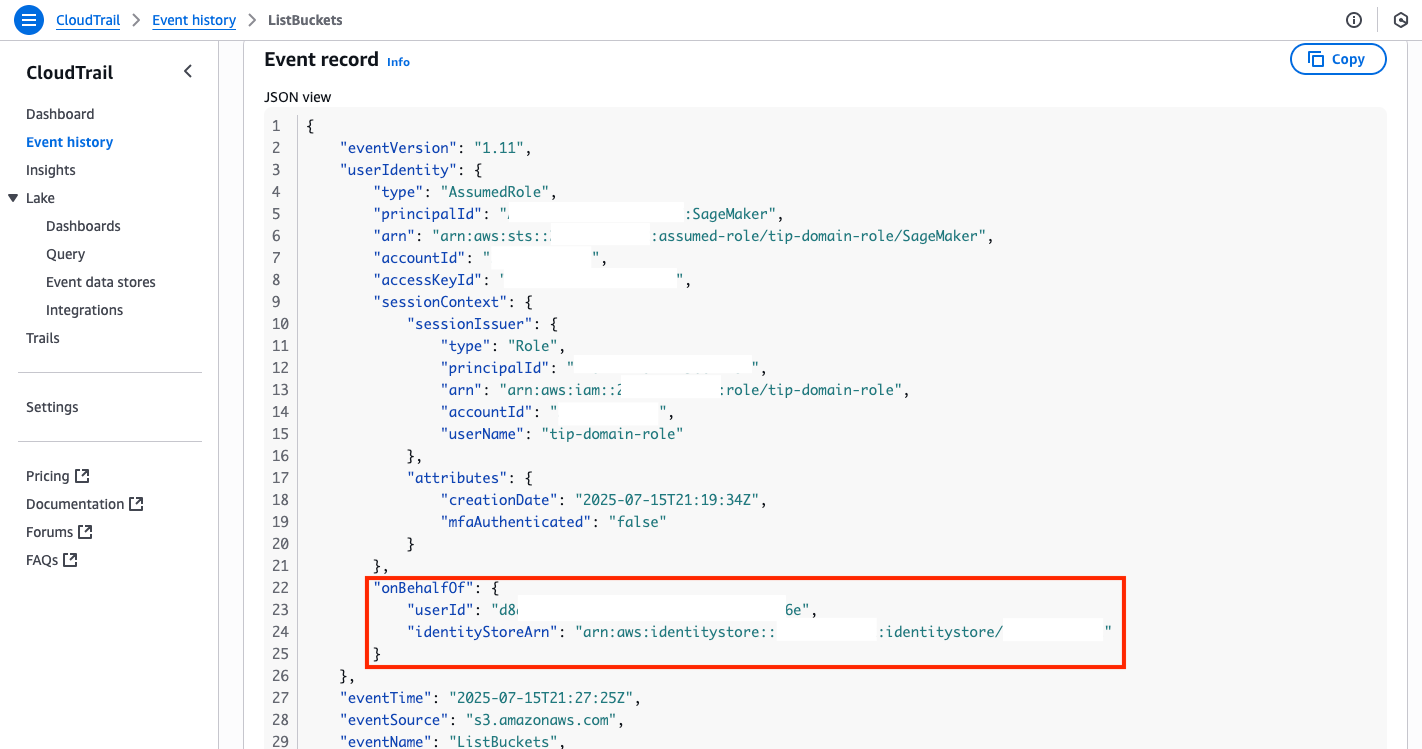

Supported services and SageMaker AI features called from a trusted identity propagation-enabled SageMaker Studio domain will have the OnBehalfOf field in CloudTrail.
Clean up
If you have created a SageMaker Studio domain for the purposes of trying out trusted identity propagation, delete the domain and its associated Amazon Elastic File System (Amazon EFS) volume to avoid incurring additional charges. Before deleting a domain, you must delete all the users and their associated spaces and applications. For detailed instructions, see Stop and delete your Studio running applications and spaces.
If you created a SageMaker training job, they are ephemeral, and the compute is shut down automatically when the job is complete.
Athena is a serverless analytics service that charges per query billing. No cleanup is necessary, but for best practices, delete the workgroup to remove unused resources.
Conclusion
In this post, we showed you how to enable trusted identity propagation for SageMaker AI domains that use IAM Identity Center as the mode of authentication. With trusted identity propagation, administrators can manage user authorization to other AWS services through the user’s physical identity in conjunction with IAM roles. Administrators can streamline permissions management by maintaining a single domain execution role and manage granular access to other AWS services and data sources through the user’s identity. In addition, trusted identity propagation supports auditing, so administrators can track user activity without the need for managing a role for each user profile.
To learn more about enabling this feature and its use cases, see Trusted identity propagation use cases and Trusted identity propagation with Studio. This post covered a subset of supported applications; we encourage you to check out the documentation and choose the services that best serve your use case and share your feedback!
About the authors














