





Picture this: your machine learning (ML) team has a promising model to train and experiments to run for their generative AI project, but they’re waiting for GPU availability. The ML scientists spend time monitoring instance availability, coordinating with teammates over shared resources, and managing infrastructure allocation. Simultaneously, your infrastructure administrators spend significant time trying to maximize utilization and minimize idle instances that lead to cost-inefficiency.
This isn’t a unique story. We heard from customers that instead of managing their own infrastructure and job ordering, they wanted a way to queue, submit, and retry training jobs while using Amazon SageMaker AI to perform model training.
AWS Batch now seamlessly integrates with Amazon SageMaker Training jobs. This integration delivers intelligent job scheduling and automated resource management while preserving the fully managed SageMaker experience your teams are familiar with. ML scientists can now focus more on model development and less on infrastructure coordination. At the same time, your organization can optimize the usage of costly accelerated instances, increasing productivity and decreasing costs. The following example comes from Toyota Research Institute (TRI):
“With multiple variants of Large Behavior Models (LBMs) to train, we needed a sophisticated job scheduling system. AWS Batch’s priority queuing, combined with SageMaker AI Training Jobs, allowed our researchers to dynamically adjust their training pipelines—enabling them to prioritize critical model runs, balance demand across multiple teams, and efficiently utilize reserved capacity. The result was ideal for TRI: we maintained flexibility and speed while being responsible stewards of our resources.”
–Peter Richmond, Director of Information Engineering
In this post, we discuss the benefits of managing and prioritizing ML training jobs to use hardware efficiently for your business. We also walk you through how to get started using this new capability and share suggested best practices, including the use of SageMaker training plans.
Solution overview
AWS Batch is a fully managed service for developers and researchers to efficiently run batch computing workloads at different scales without the overhead of managing underlying infrastructure. AWS Batch dynamically provisions the optimal quantity and type of compute resources based on the volume and specific requirements of submitted batch jobs. The service automatically handles the heavy lifting of capacity planning, job scheduling, and resource allocation, so you can focus on your application logic rather than managing underlying infrastructure.
When you submit a job, AWS Batch evaluates the job’s resource requirements, queues it appropriately, and launches the necessary compute instances to run the job, scaling up during peak demand and scaling down to zero when no jobs are running. Beyond basic orchestration, AWS Batch includes intelligent features like automatic retry mechanisms that restart failed jobs based on configurable retry strategies, and fair share scheduling to manage equitable resource distribution among different users or projects by preventing a single entity from monopolizing compute resources. This can be especially useful if your organization has production workloads that should be prioritized. AWS Batch has been used by many customers with submit-now, run-later semantics for scheduling jobs and achieving high utilization of compute resources on Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), AWS Fargate, and now SageMaker Training jobs.
AWS Batch for SageMaker Training jobs consists of the following key components that work together to deliver seamless batch processing:
- Training jobs serve as blueprints that specify how jobs should run, including Docker container images, instance types, AWS Identity and Access Management (IAM) roles, and environment variables
- Job queues act as holding areas where jobs wait to be executed, with configurable priority levels that determine execution order
- Service environments define the underlying infrastructure maximum capacity
With these foundations, AWS Batch can retry for transient failures and provide comprehensive queue visualization, addressing critical pain points that have been challenging to address with ML workflows. The integration provides automatic retry for transient failures, bulk job submission, enabling scientists to focus on model improvements instead of infrastructure management.
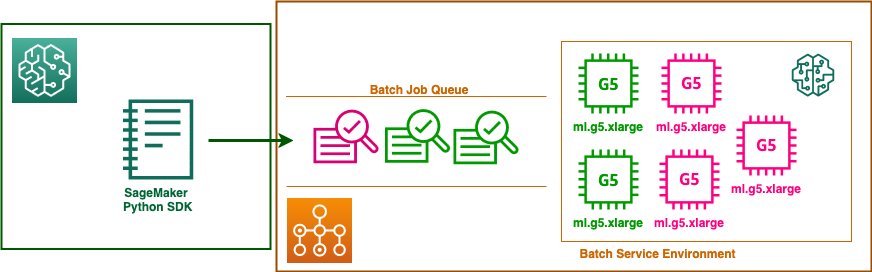
To use an AWS Batch queue for SageMaker Training jobs, you must have a service environment and a job queue. The service environment represents the Amazon SageMaker AI capacity limits available to schedule, expressed through maximum number of instances. The job queue is the scheduler interface researchers interact with to submit jobs and interrogate job status. You can use the AWS Batch console, or AWS Command Line Interface (AWS CLI) to create these resources. In this example, we create a First-In-First-Out (FIFO) job queue and a service environment pool with a limit of five ml.g5.xlarge instances using the AWS Batch console. The following diagram illustrates the solution architecture.

Prerequisites
Before you deploy this solution, you must have an AWS account with permissions to create and manage AWS Batch resources. For this example, you can use these Sample IAM Permissions along with your SageMaker AI execution role.
Create a service environment
Complete the following steps to create the service environment you will associate with the training job queue:
- On the AWS Batch console, choose Environments in the navigation pane.
- Choose Create environment, then choose Service environment.
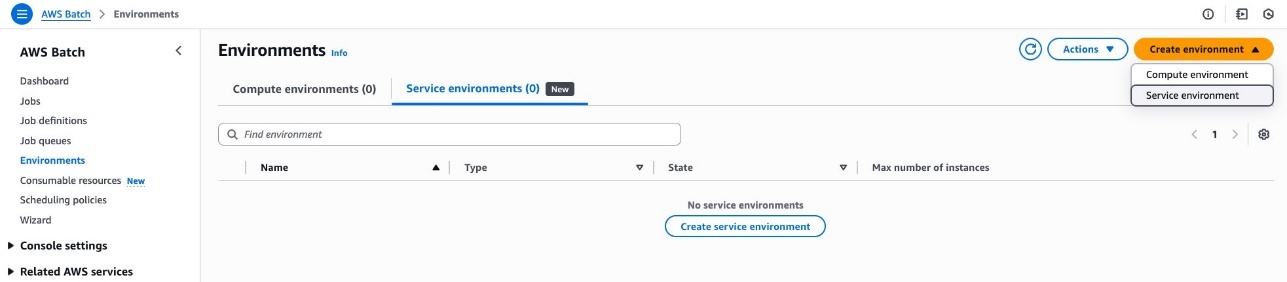

- Provide a name for your service environment (for this post, we name it
ml-g5-xl-se). - Specify the maximum number of compute instances that will be available to this environment for model training (for this post, we set it to 5). You can update the value for your capacity limit later as needed.
- Optionally, specify tags for your service environment.
- Create your service environment.
Create a job queue
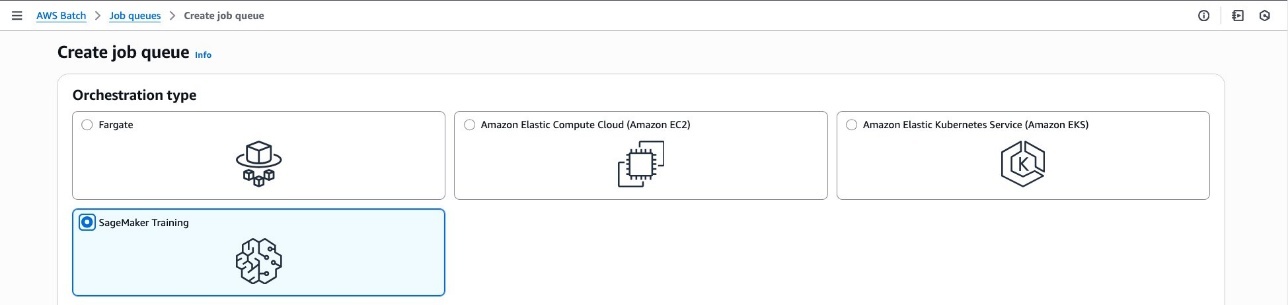
Complete the following steps to create your job queue:
- On the AWS Batch console, choose Job queues in the navigation pane.
- Choose Create job queue.
- For Orchestration type, select SageMaker Training.

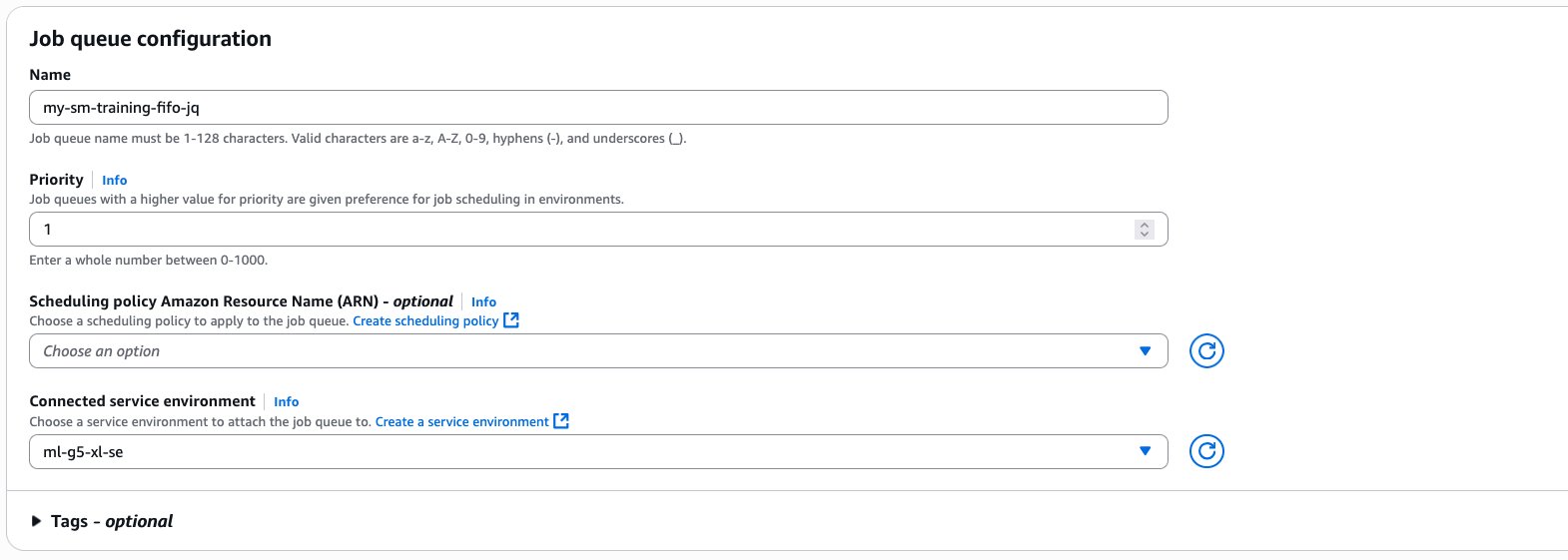
- Provide a name for your job queue (for this post, we name it
my-sm-training-fifo-jq). - For Connected service environment, choose the service environment you created.
- Leave the remaining settings as default and choose Create job queue.

You can explore fair-share queues by reading more about the scheduling policy parameter. Additionally, you can use job state limits to configure your job queue to take automatic action to unblock itself in the event that a user submitted jobs that are misconfigured or remain capacity constrained beyond a configurable period of time. These are workload-specific parameters that you can tune to help optimize your throughput and resource utilization.
Submit SageMaker Training jobs to AWS Batch from the SageMaker Python SDK
The newly added aws_batch module within the SageMaker Python SDK allows you to programmatically create and submit SageMaker Training jobs to an AWS Batch queue using Python. This includes helper classes to submit both Estimators and ModelTrainers. You can see an example of this in action by reviewing the sample Jupyter notebooks. The following code snippets summarize the key pieces.
Complete the basic setup steps to install a compatible version of the SageMaker Python SDK:
To use the job queue you configured earlier, you can refer to it by name. The Python SDK has built-in support for the integration within the TrainingQueue class:
For this example, we focus on the simplest job that you can run, either a class that inherits from EstimatorBase or ModelTrainer, a hello world job. You can use a ModelTrainer or Estimator, such as PyTorch, instead of the placeholder:
Submitting an estimator job is as straightforward as creating the estimator and then calling queue.submit. This particular estimator doesn’t require any data, but in general, data should be provided by specifying inputs. Alternatively, you can queue a ModelTrainer using AWS Batch by calling queue.submit, shown in the following code:
Monitor job status
In this section, we demonstrate two methods to monitor the job status.
Display the status of jobs using the Python SDK
The TrainingQueue can list jobs by status, and each job can be described individually for more details:
After a TrainingQueuedJob has reached the STARTING status, the logs can be printed from the underlying SageMaker AI training job:
Display the status of jobs on the AWS Batch console
The AWS Batch console also provides a convenient way to view the status of running and queued jobs. To get started, navigate to the overview dashboard, as shown in the following screenshot.
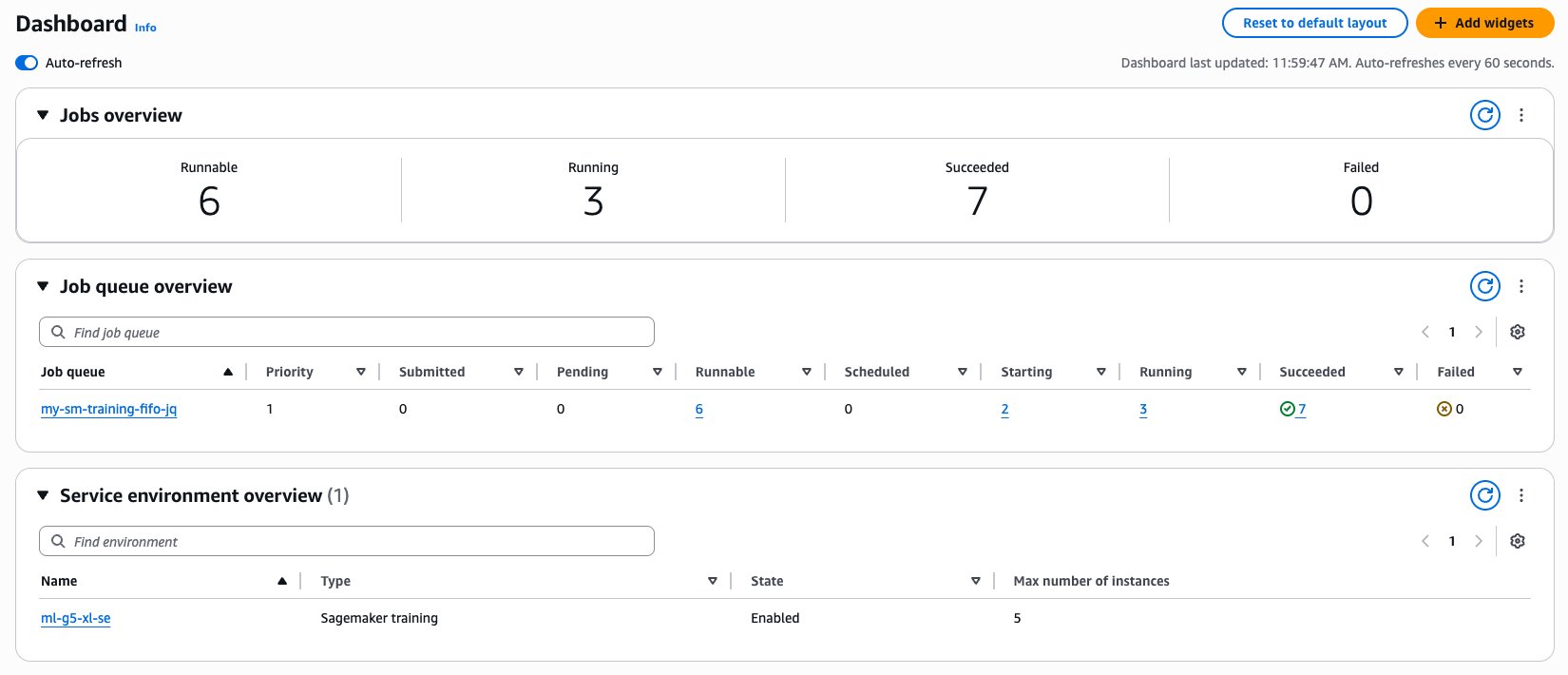

From there, you can choose on the number underneath the AWS Batch job state you’re interested in to see the jobs in your queue that are in the given state.
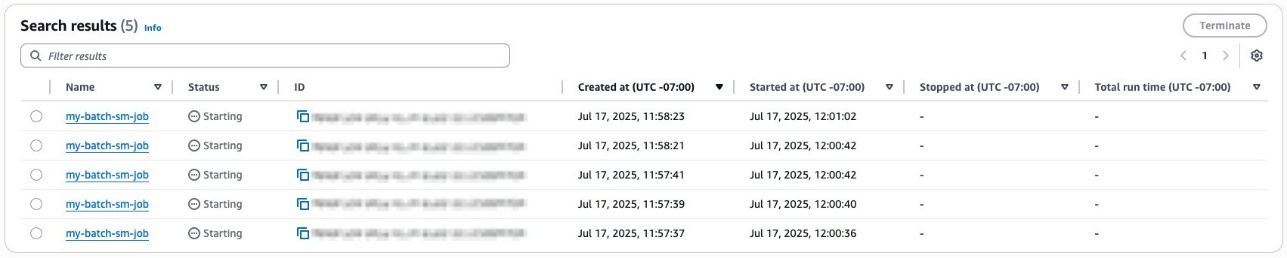

Choosing an individual job in the queue will bring you to the job details page.


You can also switch to the SageMaker Training job console for a given job by choosing the View in SageMaker link on the AWS Batch job details page. You will be redirected to the corresponding job details page on the SageMaker Training console.
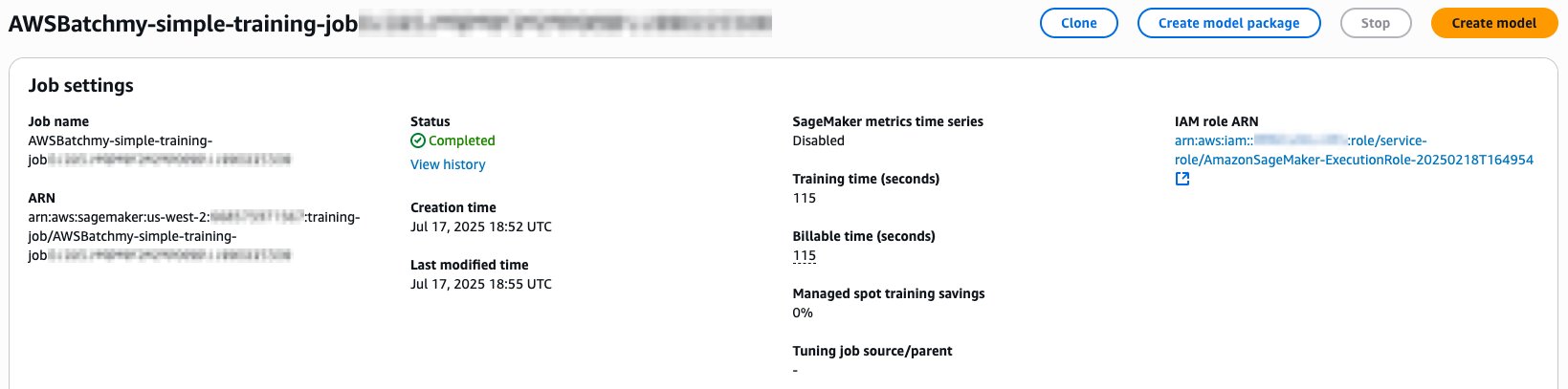

Whether you use the AWS Batch console or a programmatic approach to inspecting the jobs in your queue, it is generally useful to know how AWS Batch job states map to SageMaker Training job states. To learn how that mapping is defined, refer to the Batch service job status overview page found within the Batch user guide.
Best practices
We recommend creating dedicated service environments for each job queue in a 1:1 ratio. FIFO queues deliver basic fire-and-forget semantics, whereas fair share scheduling queues provide more sophisticated scheduling, balancing utilization within a share identifier, share weights, and job priority. If you don’t need multiple shares but want to assign a priority on job submission, we recommend creating a fair share scheduling queue and using a single share within it for all submissions.
This integration works seamlessly with SageMaker Flexible Training Plans (FTP); simply set the TrainingPlanArn as part of the CreateTrainingJob JSON request, which is passed to AWS Batch. If the goal is for a single job queue to keep that FTP fully utilized, setting capacityLimits on the service environment to match the capacity allocated to the flexible training plan will allow the queue to maintain high utilization of all the capacity.
If the same FTP needs to be shared among many teams, each with a firm sub-allocation of capacity (for example, dividing a 20-instance FTP into 5 instances for a research team and 15 instances for a team serving production workloads), then we recommend creating two job queues and two service environments. The first job queue, research_queue, would be connected to the research_environment service environment with a capacityLimit set to 5 instances. The second job queue, production_queue, would be connected to a production_environment service environment with a capacity limit of 15. Both research and production team members would submit their requests using the same FTP.
Alternatively, if a strict partition isn’t necessary, both teams can share a single fair share scheduling job queue with separate share identifiers, which allows the queue to better utilize available capacity.
We recommend not using the SageMaker warm pool feature, because this can cause capacity to be idle.
Conclusion
In this post, we covered the new capability to use AWS Batch with SageMaker Training jobs and how to get started setting up your queues and submitting your jobs. This can help your organization schedule and prioritize jobs, freeing up time for your infrastructure admins and ML scientists. By implementing this functionality, your teams can focus on their workloads and not waste time managing and coordinating infrastructure. This capability is especially powerful using SageMaker training plans so that your organization can reserve capacity in the quantity you need, during the time you need it. By using AWS Batch with SageMaker AI, you can fully utilize the training plan for the most efficiency. We encourage you to try out this new capability so it can make a meaningful impact in your operations!
About the Authors























